Chaining: Analysis
In chaining, the runtime of insert/remove and lookup is proportional to the number of keys in the given chain. So, to analyze the complexity, we need to analyze the length of the chains.
Best case: if we are lucky, the number of elements inserted is smaller than the capacity of the table, and we have a stellar hashing procedure with no collision! The performance for insert/remove and search is $O(1)$.
Worst case: if we're unlucky with the keys we encounter, or if we have a poorly implemented hashing procedure, all keys may hash to the same bucket.

In the worst-case, the performance is $O(n)$ where $n$ is the number of items stored in the hash table. (Assuming the auxiliary is a linked lists).
Average case: under the assumption of uniform hashing, we expect each bucket to be of size $(n/M)$ where $n$ is the number of items stored in the hash table and $M$ is its size (number of array/table slots). Notice this ratio is the load factor. Therefore, the performance is $O(\alpha)$.
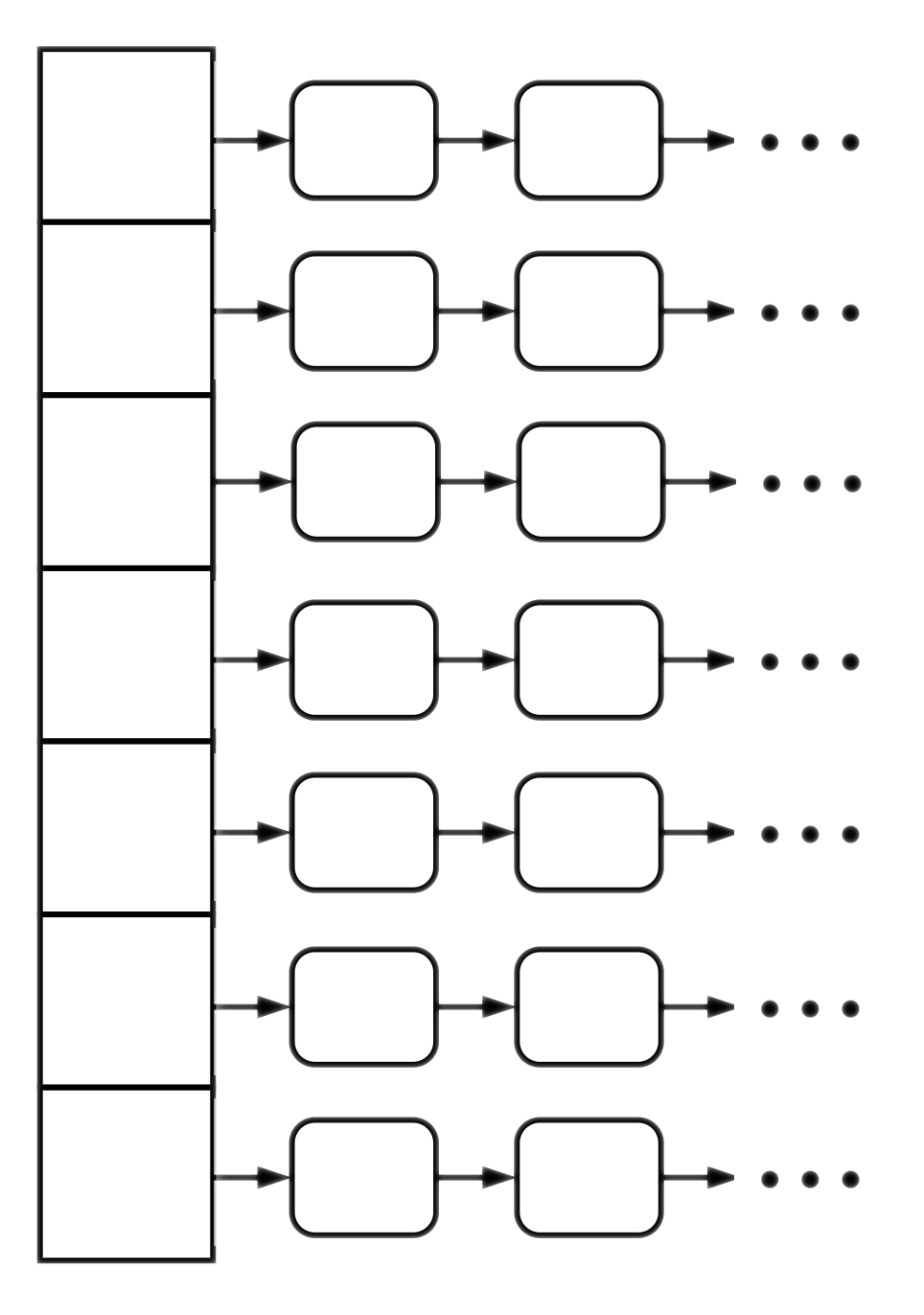
If we keep the $\alpha$ bounded by a small constant (preferably below $1$) we get expected constant runtime operations.
Notice the performance also depends on the choice of the auxiliary data structures. The most common choices are:
| Chaining in each bucket | find | delete | insert |
|---|---|---|---|
| (Unordered) linked list | $O(\alpha)$ | $O(\alpha)$ | $O(\alpha)$ |
| (Ordered) dynamic array | $O(\lg \alpha)$ | $O(\alpha)$ | $O(\alpha)$ |
| (Self-balancing) binary search tree | $O(\lg \alpha)$ | $O(\lg \alpha)$ | $O(\lg \alpha)$ |
In Java, the HashMap is implemented using chaining strategy with a linked list auxiliary data structure. Java's HashMap maintains a load factor $\alpha \le 0.75$ and when the number of elements is reached to a certain limit, it switches to a BST for the auxiliary data structure.
Resources
- Wikipedia entry on Hash Table: Performance.