Lazy Deletion
We learned from the previous exercise that if we delete an item (i.e. set its table entry to null), then when we search for an item that had collided with the deleted item, we may incorrectly conclude that the target item is not in the table. (Because we will have stopped our search prematurely.)
The issue with removal
When an item is deleted, we cannot just set its table entry to NULL.
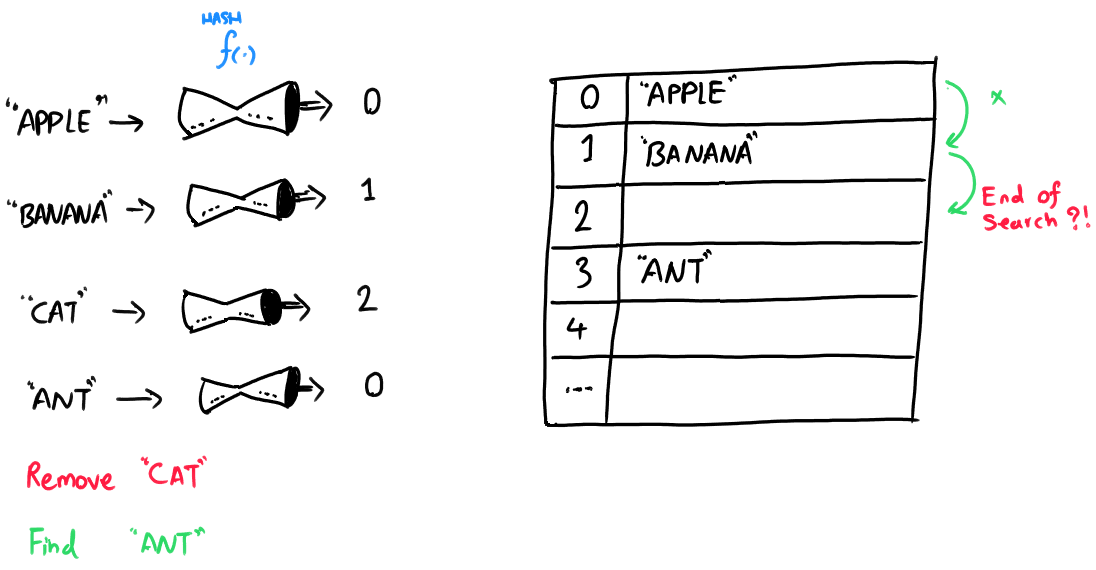
If we do, then when we search for an item that may have collided with the deleted item, we may incorrectly conclude that the item is not in the table. Because the item that collided was inserted after the deleted item, we will have stopped our search prematurely.
The solution is lazy deletion: flag the item as deleted (instead of actually deleting it). This strategy is also known as placing a tombstone ⚰️ over the deleted item!

Source: craftinginterpreters.com
Place a tombstone!
When an item is deleted, replace the deleted item with a tombstone (to mark it as "deleted").
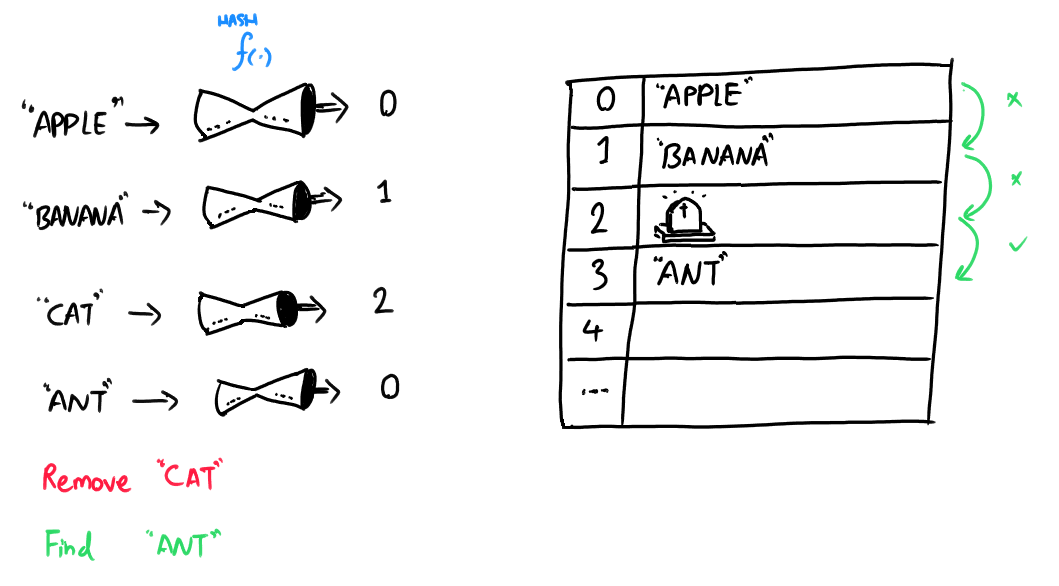
By storing a tombstone (a sentinel value) when an item is deleted, we force the search algorithm to keep looking until either the desired item is found or a NULL value, representing a free cell, is located.
Future inserts can overwrite tombstones, but lookups treat them as collisions.
For the previous exercise, we insert a tombstone (TS) in place of the deleted entry:
| [ 0 ] | [ 1 ] | [ 2 ] | [ 3 ] | [ 4 ] | [ 5 ] | [ 6 ] | Output | |
|---|---|---|---|---|---|---|---|---|
| Current State | 86 | 700 | 5005 | 1111 | 2332 | 8333 | ||
remove(2332) | 86 | 700 | 5005 | 1111 | TS | 8333 | ||
find(8333) | 86 | 700 | 5005 | 1111 | TS | 8333 | 3,4,5,6: F |
The find(8333) will go over the indices as follows:
[3] --> [4] --> [5] (TOMBSTONE) --> [6] --> FOUND
Without inserting a tombstone in place of $2332$, find(8333) would not know to continue after finding no number at index $5$.